Elasticsearch是一个基于Lucene的分布式搜索引擎,用于解决传统数据库在全文检索、海量数据搜索和实时分析方面的不足。它通过倒排索引、分词器和相关性评分等核心特性实现高效搜索,并可与Spring Boot集成进行开发。在生产环境中,需注意数据同步、高可用部署及深度分页等进阶问题。
参考整理自up主鱼皮的教程:https://www.bilibili.com/opus/1179932214682451986
1.基础学习
一、 什么是 Elasticsearch?
Elasticsearch(简称 ES) 是一个基于 Lucene 的开源、分布式、RESTful 搜索引擎。它不仅是一个数据库,更是为了解决传统关系型数据库(如 MySQL)在全文检索、海量数据搜索和实时分析方面的不足而设计的。
为什么不用 MySQL 的 LIKE 查询?
- 性能差:
LIKE '%关键词%'无法利用索引,数据量大时查询极慢。 - 结果不精准:无法根据相关性进行排序(比如“最匹配”的内容排在前面)。
- 缺乏分词能力:难以处理复杂的自然语言搜索。
二、 核心概念与实战操作
1. 核心术语对照
| ES 概念 | MySQL 对应概念 | 说明 |
|---|---|---|
| Index (索引) | Table (表) | 存储数据的容器。 |
| Mapping (映射) | Schema (表结构) | 定义字段类型、分词规则等。 |
| Document (文档) | Row (行) | 以 JSON 格式存储的具体数据。 |
2. 基础操作(DSL 语法)
ES 使用 JSON 格式的 DSL(领域特定语言)进行交互,建议配合可视化工具 Kibana 使用。
创建索引:需指定字段类型,也就是映射mapping。
text用于全文检索(会分词),keyword用于精确匹配(不分词)。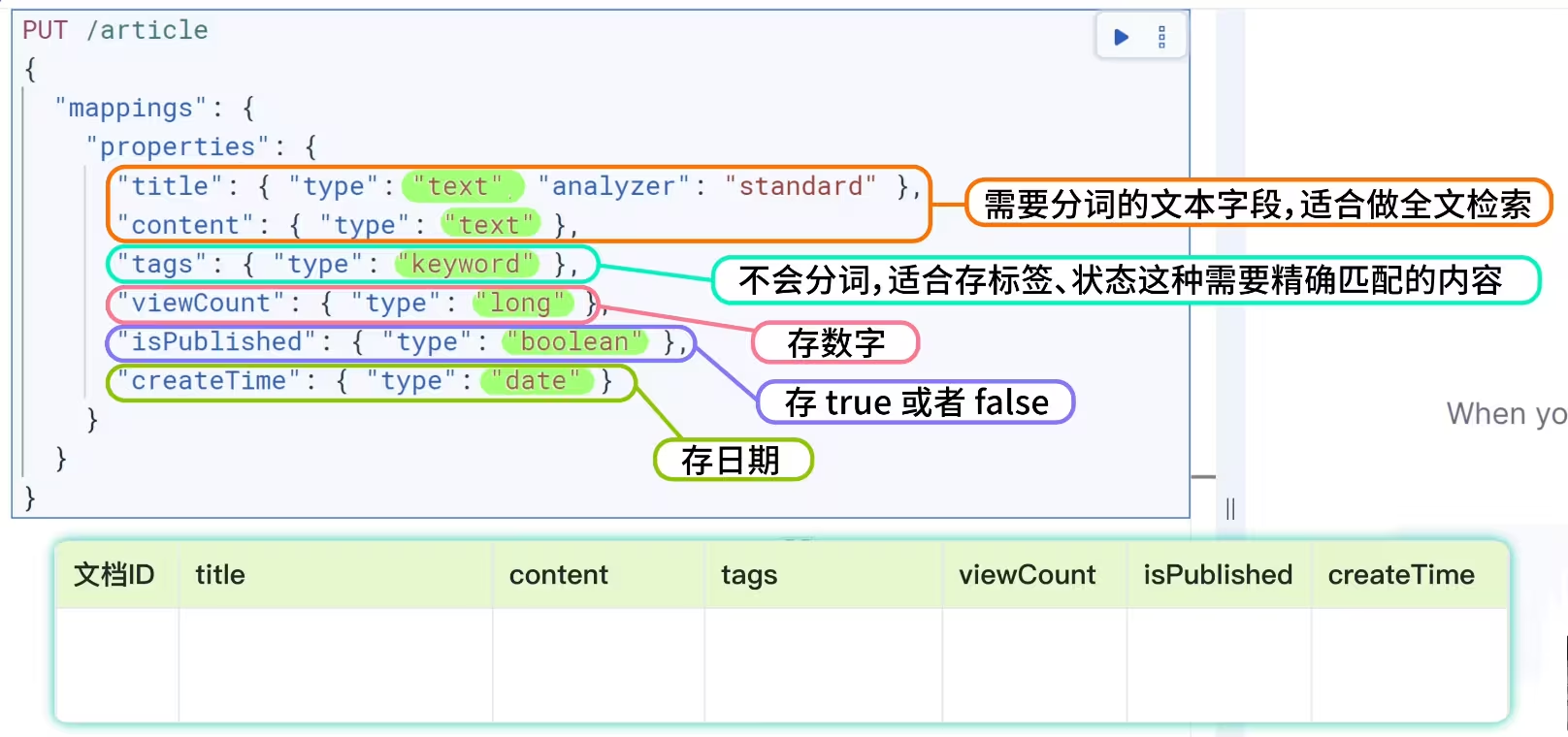
插入数据:直接发送 POST 请求提交 JSON 文档。

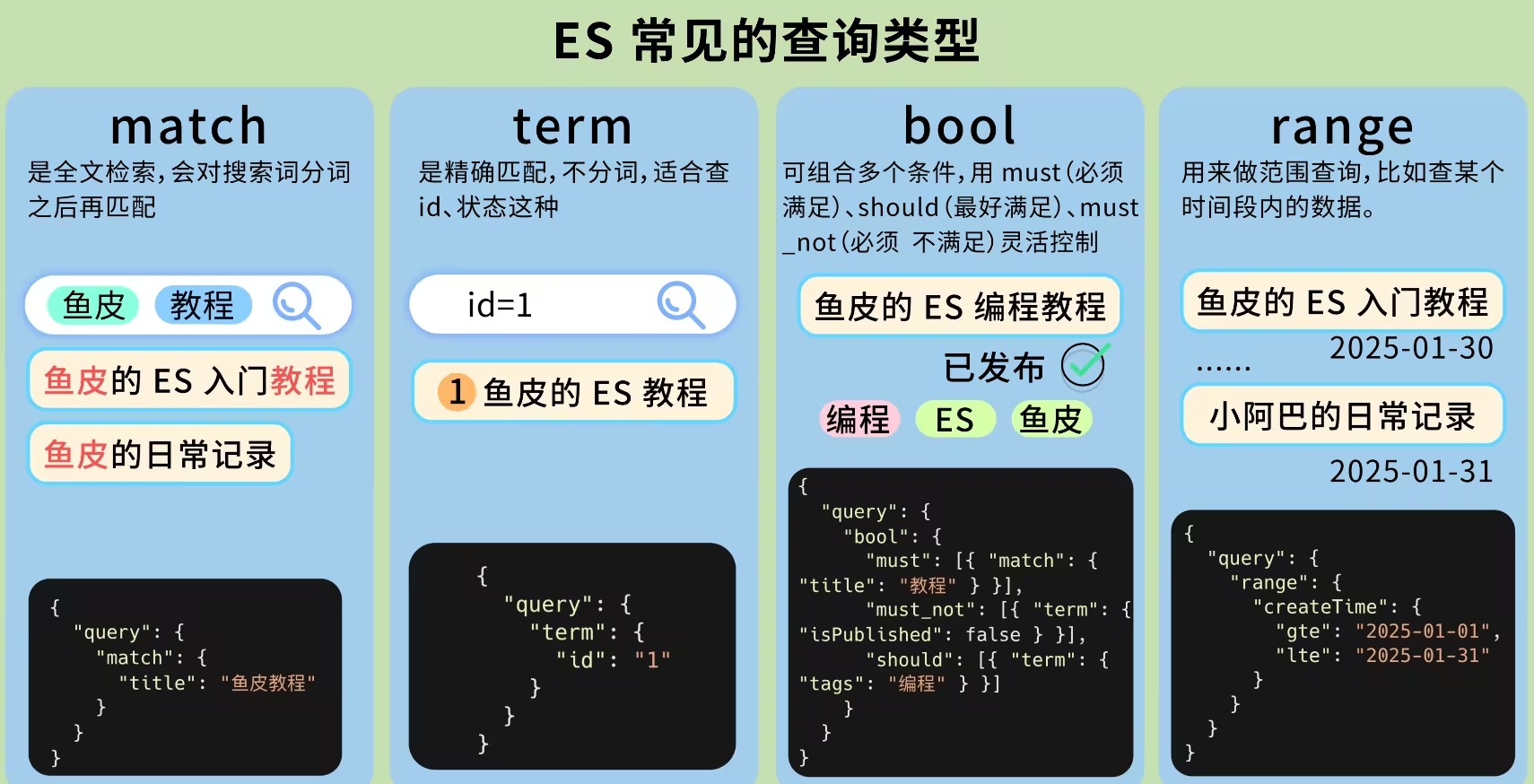
- 搜索数据:使用
match进行全文搜索,ES 会自动分词并计算匹配度。
3. Java 客户端开发
在生产中,通常使用 Spring Data Elasticsearch。它允许开发者通过定义接口(继承 ElasticsearchRepository)并使用注解(如 @Document)来操作 ES,就像使用 MyBatis-Plus 一样简单。后文会有代码示例
三、 ES 为什么这么快?(核心特性)
1. 倒排索引 (Inverted Index)
这是 ES 的灵魂。它不直接存整行数据,而是记录单词 -> 文档 ID 列表的映射。搜索时,系统先对搜索词进行分词,然后通过倒排索引直接定位包含这些词的文档,无需全表扫描。
2. 分词器 (Analyzer)
- 标准分词器:对中文支持较差(按字拆分)。
- IK 分词器:中文搜索必备,提供
ik_smart(智能切分)和ik_max_word(最细粒度切分)模式。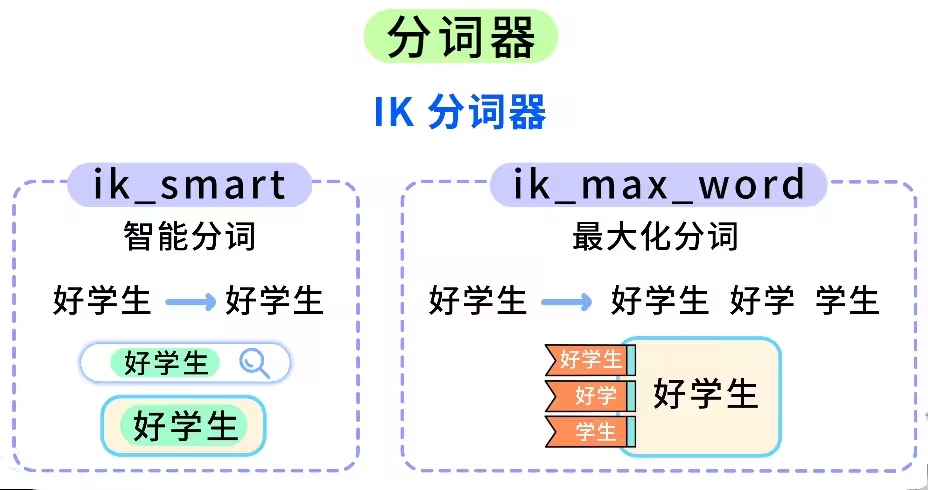
3. 相关性评分
ES 默认采用 BM25 算法,通过词频(TF)、逆文档频率(IDF)和文档长度来计算分数(_score),确保用户最想要的结果排在最前面。 
四、 生产环境的挑战与方案
1. 数据同步
由于 ES 和 MySQL 是独立系统,需要解决数据一致性问题:
- 定时任务:适合实时性要求不高的场景。
- 双写:代码层面同时写入两端,但需处理写入失败。
- Canal 监听:实时监听 MySQL 的 Binlog 变更并同步,延迟低。
2. 高可用与扩展
- 集群部署:通过多节点(主节点、数据节点)保证服务不宕机。
- 分片 (Shard):将大索引拆分存放在不同节点,提升存储上限和并发能力。
- 副本 (Replica):分片的备份,防止节点损坏导致数据丢失。
3. 常见进阶问题
- 深度分页:ES 默认限制查询前 10,000 条。深层次翻页建议使用
search_after。 - ELK 生态:Elasticsearch (存储) + Logstash (收集) + Kibana (展示),是目前主流的日志分析方案。
建议:学习 ES 最好的方式是动手实践,先在本地搭建一个单机版环境,尝试通过 Kibana 练习各种 DSL 查询。
2.代码实现
我们通常会选择在 Spring Boot 项目中集成 Spring Data Elasticsearch。这是目前 Java 后端最主流、也是最高效的开发方式。
1. 环境准备与配置
首先,在项目的 pom.xml 中引入依赖:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-elasticsearch</artifactId>
</dependency>
在 application.yml 中配置 ES 服务器地址:
spring:
elasticsearch:
uris: http://localhost:9200
2. 定义实体类(Mapping 映射)
通过注解将 Java 对象映射为 ES 的索引结构。text 类型用于搜索,keyword 用于精确过滤。
@Data
@Document(indexName = "article") // 指定索引名称
public class Article {
@Id
private Long id;
// type = Text 表示支持全文检索,analyzer 指定分词器
@Field(type = FieldType.Text, analyzer = "ik_max_word", searchAnalyzer = "ik_smart")
private String title;
@Field(type = FieldType.Text, analyzer = "ik_max_word")
private String content;
// type = Keyword 表示不分词,直接匹配
@Field(type = FieldType.Keyword)
private String category;
@Field(type = FieldType.Date, format = DateFormat.basic_date_time)
private LocalDateTime createTime;
}
3. 编写 Repository 接口
这是 Spring Data 的精髓,你只需要定义方法名,框架会自动帮你生成 DSL 查询语句。
public interface ArticleRepository extends ElasticsearchRepository<Article, Long> {
// 自动解析:根据标题全文检索
List<Article> findByTitle(String title);
// 自动解析:根据分类精确匹配
List<Article> findByCategory(String category);
// 复合查询:标题匹配且分类一致
List<Article> findByTitleAndCategory(String title, String category);
}
4. 高级搜索:使用 ElasticsearchTemplate
如果 Repository 的方法名无法满足复杂的业务逻辑(如高亮、聚合、复杂的布尔过滤),可以使用 ElasticsearchTemplate。
示例:带高亮和过滤的复合搜索
@Autowired
private ElasticsearchRestTemplate elasticsearchRestTemplate;
public void complexSearch(String keyword) {
// 1. 构建查询条件(类似 SQL 的 WHERE)
NativeSearchQuery searchQuery = new NativeSearchQueryBuilder()
.withQuery(QueryBuilders.boolQuery()
.must(QueryBuilders.matchQuery("title", keyword)) // 必须匹配标题
.should(QueryBuilders.matchQuery("content", keyword))) // 内容匹配可加分
.withHighlightFields(new HighlightBuilder.Field("title")) // 设置高亮字段
.withPageable(PageRequest.of(0, 10)) // 分页
.build();
// 2. 执行搜索
SearchHits<Article> searchHits = elasticsearchRestTemplate.search(searchQuery, Article.class);
// 3. 处理高亮结果
searchHits.getSearchHits().forEach(hit -> {
Article article = hit.getContent();
List<String> highlightTitle = hit.getHighlightField("title");
if (!highlightTitle.isEmpty()) {
article.setTitle(highlightTitle.get(0)); // 替换为带 <em> 标签的内容
}
System.out.println("搜索结果: " + article);
});
}
5. 核心逻辑总结
在实际开发中,代码流程通常是:
- MySQL 写入:文章发布成功。
- 触发同步:通过
articleRepository.save(article)同步到 ES。 - 用户搜索:调用自定义的
search方法,获取经过分词和评分排序后的结果。
注意:
在本地调试时,请确保已经安装了 IK 分词器 插件,否则代码中的analyzer = "ik_max_word"会导致 ES 报错。